打造 SkillsJars Helper:让 AI Agent Skill 在 IDE 中可视化分发与管理的 IDEA 插件

打造 SkillsJars Helper:让 AI Agent Skill 在 IDE 中可视化分发与管理的 IDEA 插件
dong4j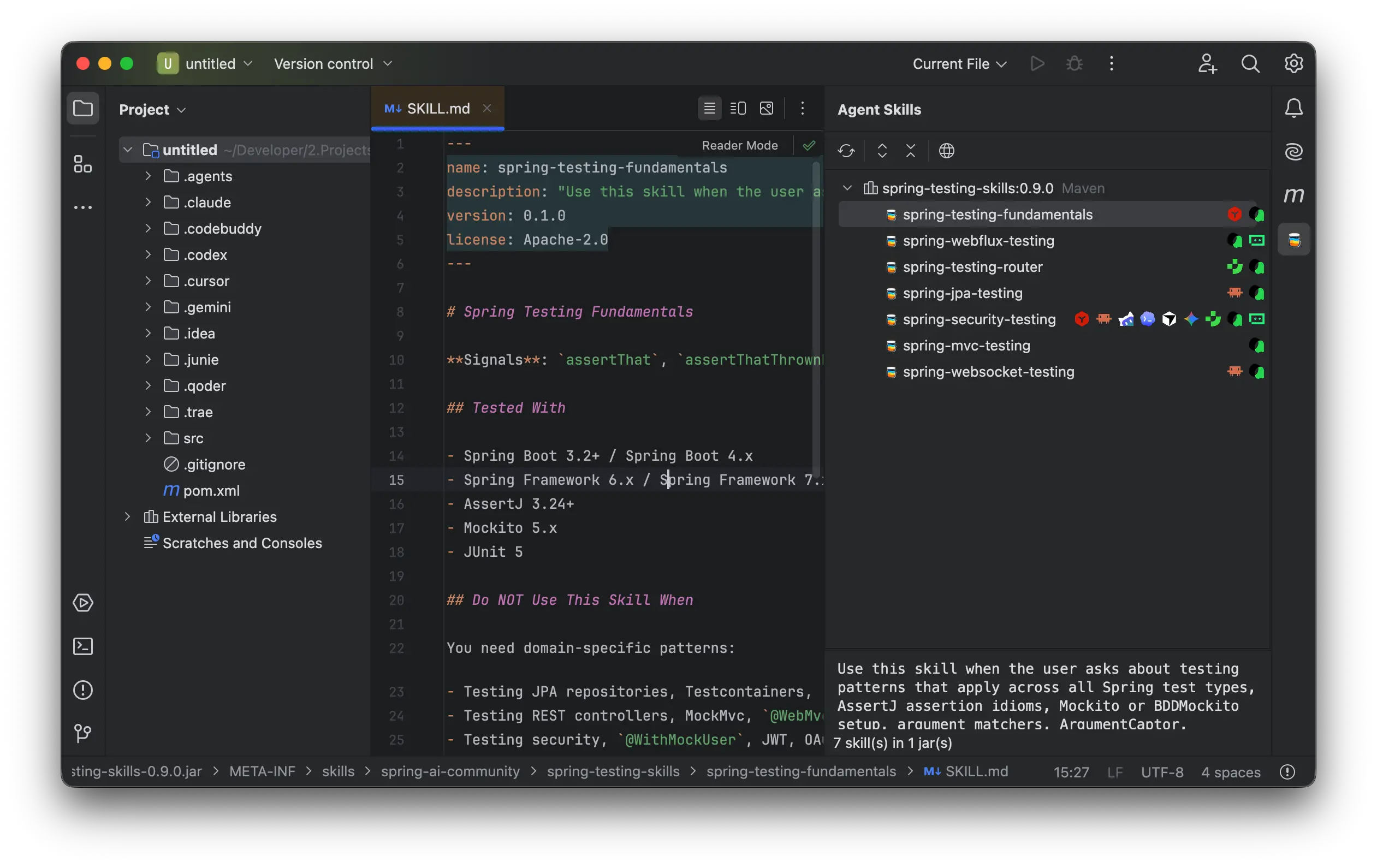
一份文档, 两类读者
我维护 Zeka Stack 这套开源框架已经几年了, 它做的事情和大部分公司里的 Spring Boot 脚手架差不多 —— 一堆 cubo-*-spring-boot-starter, 每个 Starter 提供自动配置、统一的异常 / 响应 / 日志 / 配置语义, 让业务项目少写样板代码、多走规范轨道。
过去几年, 我一直把这件事看成”给开发者写文档”。Starter 写完之后, 配套一份 README.md、几个示例工程、一份 docs/ 目录, 同事或开源用户引入 starter, 翻一翻文档, 就能上手。
但去年开始, 我越来越清楚地意识到一件事: 文档的读者变了。过去文档只给开发者看, 现在 AI 也是一种用户 —— 而且会是越来越主要的那种。当业务项目里的同事让 Cursor / Claude Code 写一段 REST Controller 的时候, AI 不会去翻我的 README, 也不知道我这个 starter 自动装了哪些 Bean, 不知道哪些 Bean 可以覆盖、哪些不应该绕过, 不知道同组件下 Servlet starter 和 Reactive starter 应该怎么选。
它会写得很快, 也会快速地偏离我设计的工程轨道。
这就引出一个矛盾: 我精心维护的工程规范, 在 AI 时代变成了一种”AI 看不见的资产”。如果不解决这个问题, 框架的价值会越来越薄 —— 反正 AI 都不读, 你的最佳实践写得再好也没人执行。
我在 [[zeka-stack-ai-native-engineering-platform|Zeka Stack 3.0: AI Native 工程平台定位升级]] 那篇里聊过这个判断, 在 让 Spring Boot Starter 天然支持 AI 那篇里聊过具体接入 SkillsJars 的过程。SkillsJars Helper 这个 IDEA 插件, 就是这条链路最后一步的产物。
一个固执观点, 终于站住了
文档应该跟着代码走 —— 意思是文档应该放在项目里, 和代码一起进行版本迭代, 而不是单独放在公司的 WIKI 知识库或者别的什么专门管理 md 文件的库里。
这个观点本身不算新, 业界叫 “Docs as Code”, 至少有十几年的历史了。它的反对面是 WIKI 派 —— 把 Confluence 当唯一真理源, 文档归文档, 代码归代码, 各走各的版本线。两边各有信徒, 这场争论从来没在公司层面分出过胜负。
我个人一直固执地站在 “Docs as Code” 这边。哪怕进的公司 Confluence 文化再浓, 我也尽量把规则、约定、设计取舍写进 README.md / docs/ / CHANGELOG.md, 让文档跟代码同库 commit、同 PR review、同版本号发布。我的理由很朴素: 跨系统的东西容易腐烂, 离开了代码上下文, 文档就会被人忘记 —— 当初写得再认真, 也只是另一个迟早过期的存档。
过去十几年, 这个观点我没真正说服过谁。大部分人听完笑笑就过去了, 一边继续在 Confluence 上堆页面, 一边继续抱怨”文档总是过时”。两个动作之间的因果关系, 没人想认。
直到 AI 进入开发流程, 这件事突然站住了脚。
原因很直接: AI 是非常不可靠的 doc reader。它不会主动跨系统去找文档, 它能读到的只有 IDE 上下文里直接可见的文件。README.md / SKILL.md / docs/ 是它的天然食谱; Confluence 页面对它来说几乎不存在 —— 理论上能搭 MCP 接进来, 但权限、认证、网络可达性、内网穿透这一连串问题, 大部分团队根本没本钱搞定, 短期内也搞不定。所以文档放在哪, 决定了 AI 能不能看见; AI 看不见的文档, 在 AI 时代就跟没写一样。
这是过去十几年没人能给我提供的论据。它不是道理上的, 是物理上的 —— 不放在代码旁边的文档, AI 真的读不到, 没有商量余地。”Docs as Code” 不再是一种偏好, 而是一种必须。
SkillsJars 这件事打动我的, 不是它技术上做了什么花样, 而是它把这个观点彻底物理化了。把 SKILL.md 跟 jar 绑成一个 artifact, 一起进 Maven Central, 一起被依赖解析, 一起按 semver 升降版本。文档想跟代码分家都做不到, 它在打包阶段就被钉死在一起了。这种”不允许分离”的设计约束, 比任何”我们规定文档必须跟代码同库”的团队公约都管用。
SkillsJars 解决了什么, 它不解决什么
为了说清楚 SkillsJars Helper 在做什么, 先得说清楚 SkillsJars 这个上游项目本身在做什么。
Agent Skills 是一类约定 —— 一个 SKILL.md 文件加上配套 references/、scripts/, 放进 AI Agent 约定的目录里 (~/.cursor/skills/, ~/.claude/skills/ 等), Agent 加载后就拿到了一份”使用说明”。这套约定本身没什么复杂的, 个人用户写一个 skill, 扔到 GitHub, 别人 git clone 再 cp 到自己的 agent 目录, 完全够用。
但放到 JVM 技术栈里 —— 我要给一个 starter / SDK 配 skill, 让所有引入这个 starter 的项目自动拿到, 让 skill 跟着 starter 的版本一起升降 —— 这套手工拷贝就完全不行了。
具体不行在哪? 几个非常直白的问题:
- 团队里五个人都用 zeka-stack-rest-servlet starter, 但每个人本地 skill 是从哪个 commit
cp过来的, 没人知道。 - starter 升级到 v3.2 之后, AI 看到的 skill 还是 v3.0 的旧规则, 写出来的代码偏离最新约定。
- 业务项目同时依赖了多个带 skill 的 starter (REST / Logging / OpenAPI), 解包的时候到底要解谁的, 漏掉一个 AI 就不知道。
- starter 的传递依赖也带 skill, 但用户根本看不到那层依赖。
SkillsJars 的解法是把 skill 纳入 JVM 生态最熟悉的分发体系: Maven 和 JAR。具体做的事情说起来非常简单 —— 在 starter 项目里维护 skills/<name>/SKILL.md, Maven 打包时, skillsjars-maven-plugin 会把它放进 JAR 的 META-INF/skills/<org>/<repo>/<skill>/ 下, 跟随 jar 一起进 Maven Central 或者私服。
使用方那一端, SkillsJars 同样提供了一个 Maven 命令做解包:
1 | ./mvnw com.skillsjars:maven-plugin:0.0.7:extract -Ddir=.cursor/skills |
这条命令会扫描当前项目的 Maven 依赖图, 把所有依赖 jar 里 META-INF/skills/ 下的 skill 全部解到指定目录 (例如 .cursor/skills/)。版本一致性、传递依赖、团队同步 —— 都解决了, 因为它走的就是 Maven 那套已经被验证过 20 年的分发体系。
SkillsJars 把 “SDK 怎么分发” 这件事彻底解决了。但它没解决一件事: 开发者每天在 IDE 里要怎么用它。
SkillsJars Helper 想解决的问题, 就是这个”怎么用”
上面那条 Maven 命令, 看起来很简单, 但实际用起来很别扭:
- 命令本身记不住, 每次都要去翻 README 或者历史命令。
- 切换目标 agent 目录就得重打命令 —— 装到 Cursor 是
-Ddir=.cursor/skills, 装到 Claude 是~/.claude/skills, 装到 Qoder 又是另一个目录。 - 解之前看不见 jar 里有什么 skill。一个 starter 到底带了一份 skill 还是三份? 内容是什么? 跟我项目场景匹配不匹配? 全靠先解了再说。
- 解完之后, IDE 里再也找不到这些文件了 —— 它们躺在用户 home 目录, 跟当前项目失去了所有可见连接。
- 重复解包没有保护, 如果用户 (或者另一个工具) 已经修改过某份 skill, 一条 extract 命令下去就被静默覆盖。
这些事情没有任何一件是 SkillsJars 上游应该解决的 —— 它的职责是定义分发体系。这些是消费端 IDE 体验该解决的事。这就是 SkillsJars Helper 想做的。
具体它做了三件事。第一件是可视化: 在 IDEA 里加一个独立的 Tool Window, 启动后扫描当前项目所有 Maven 依赖, 把 jar 内带 META-INF/skills/ 的全部找出来, 用一棵树展示。树的层级是 Maven 坐标 → skill 名字 → 内容, 点开任何一个 skill, 右边面板直接渲染 SKILL.md 全文, frontmatter 也单独高亮。整个过程不解包, 因为读 jar 里的某一个文件这件事 IntelliJ Platform 早就做得很好了, 我只是把这个能力拿来用。
第二件是一键安装: 在树上任意一个 skill 上右键, 弹出菜单 —— Install to Claude / Cursor / Codex / Gemini / Junie / Trae / Qoder / CodeBuddy / Cline。选一个目标, skill 完整拷贝到对应 Agent 目录, 同时在目标目录里留一份 .skillsjars-helper.json manifest, 记录这份 skill 来自哪个 Maven 坐标、哪个版本、文件哈希是多少。Maven extract 命令该做的事情, 用 IDE 原生右键交互完成。
第三件, 也是我自己最满意的一件, 是状态识别。manifest 的存在让升级和冲突检测变得可能。每次启动插件时, SkillsJars Helper 会回扫这 9 个 Agent 目录, 对照 manifest 里的哈希和当前 Maven 依赖图里 jar 的版本, 把每份已安装 skill 划分到 6 种状态之一: 全新可装的、与最新版一致的、有更新可拉的、被本地改过的、不属于任何已知 Maven 坐标的孤儿、以及和别的 skill 撞名的。每种状态对应不同的交互: 已是最新版的连菜单都灰掉, 被本地改过的弹三选项 (覆盖 / 跳过 / 在编辑器里打开对比)。永远不静默覆盖用户改过的文件, 是这个插件的一条死规则。
一个完整的工作流
把所有东西串起来, 一个 Zeka Stack 用户的工作流大概是这样:
业务项目 pom.xml 里写一行 cubo-rest-servlet-spring-boot-starter 的依赖, Maven 自动把 starter jar 拉到本地。这一刻, starter 携带的 skill 已经躺在 jar 里了, 但 AI 还看不见。
打开 IDEA, View → Tool Windows → Agent Skills, Tool Window 弹出来, 树里出现刚刚那个 starter, 旁边带一个 NEW 徽标。点开看一眼 SKILL.md, 确认这正是我要的”REST Servlet 场景的工程规范”。右键 → Install to Cursor, 完成。
接下来这个项目里, Cursor 写 REST Controller 时, 会自动读取这份 skill, 知道这个项目用的是 Servlet 而非 Reactive, 知道要走统一异常模型而不是临时拼 JSON 错误结构, 知道哪些 Bean 可以覆盖、哪些不应该。AI 不再是泛泛地写 Spring Boot, 而是沿着 Zeka Stack 定义好的工程轨道前进。
starter 升级到下一个版本时, 业务项目 pom.xml 改一下版本号, Maven Reimport, 回到 Tool Window, 那份 skill 自动变成 OUTDATED 徽标, 右键 Update, 一气呵成。
这就是我想要的体验。CLI 命令本来可以做的事情, 没必要让开发者再去记忆和敲打 —— IDE 应该是这个体验的最终承载形态。
还没做和接下来要做的
发出去的是一期 + 二期: 扫描 / 预览 / 导出 / 状态识别这条主线已经齐了。后续还想推进几件事。
最近的一件是发布前的规范检查。如果你是 starter 作者, 在 push 一份新 SKILL.md 之前, 应该在 IDE 里就能预检 —— name 跟目录名对得上吗、必填字段全吗、allowed-tools 字段里的命令安全吗。这部分的能力我会和我另一个插件 Skill Inspector 联动, 两者职责分明: SkillsJars Helper 管”装包 / 解包 / 安装”这条 SDK 分发链路, Skill Inspector 管 “SKILL.md 内容本身”的质量。一个生产端预检, 一个消费端管理。
中远期的一件是Gradle 扫描器。当前只支持 Maven, 但越来越多的 JVM 项目走 Gradle, 这件事是迟早要做的。插件内部预留了 skillSourceScanner 扩展点, 实现起来更多是工作量问题, 思路是清楚的 —— 任何第三方插件也都可以自己实现这个扩展点, 比如把 SBT 或者 ivy 这种偏门生态接进来。
更远的一件是 AI 集成, 这部分目前还没动。我想做的事情大概有几条: 一是项目刚创建出来时, 让插件根据 pom.xml 里出现的依赖、项目语言、框架特征, 用 LLM 推荐几个匹配的 skill, 提示 “你这个项目可能需要这些”; 二是反过来, 如果项目里有多个 starter 都带了 skill, 而开发者只想要其中两个, 让 LLM 帮忙判断 skill 之间是否会有冲突或者重复; 三是甚至更前置的 —— 给一段需求描述, 让 LLM 告诉你应该用 Zeka Stack 里的哪个 starter, 然后顺手装好它的 skill。
听上去有点科幻, 但反过来想: 现在大家用 IDE 装 Maven 库, 谁还自己一个一个搜? 大部分时候是某个工具或者某个同事告诉你 “你这个场景应该用这个库”。AI 应该能扮演那个同事。
下载和源码
- JetBrains Marketplace: https://plugins.jetbrains.com/plugin/31935-skillsjars-helper
- 开源仓库: https://github.com/dong4j/skillsjars-helper
- 官网 / 完整说明: https://skillsjars-helper.dong4j.site
- 上游 SkillsJars: https://www.skillsjars.com/
- 作者其他 JetBrains 插件 (vendor 页): https://plugins.jetbrains.com/vendor/9afaba35-91ea-4364-8ced-64db868dd23e
MIT 协议, 0 外部依赖, 不联网, 不收集数据。装上不喜欢直接卸载, 不会留任何痕迹 —— 唯一的痕迹是你已经 Install 到 agent 目录的那些 skill, 它们本来就属于你的 agent。
相关阅读
- [[zeka-stack-skillsjars-ai-native-starter|让 Spring Boot Starter 天然支持 AI: Zeka Stack 接入 SkillsJars 的一次探索]] —— SkillsJars Helper 这条链路的上游故事, 讲清楚为什么要给 starter 写 SKILL.md。
- [[zeka-stack-ai-native-engineering-platform|Zeka Stack 3.0: AI Native 工程平台定位升级]] —— 整条 AI Native 工程平台的全景图, SkillsJars 只是这张图里的一块拼图。
- Skill Inspector —— SKILL.md 本身的 Linter, 写 skill 时配套用。两个插件一对, 一个管生产端检查, 一个管消费端分发。



























