打造 Skill Inspector:一款 AI Agent Skill 的 IDE Linter 插件

打造 Skill Inspector:一款 AI Agent Skill 的 IDE Linter 插件
dong4j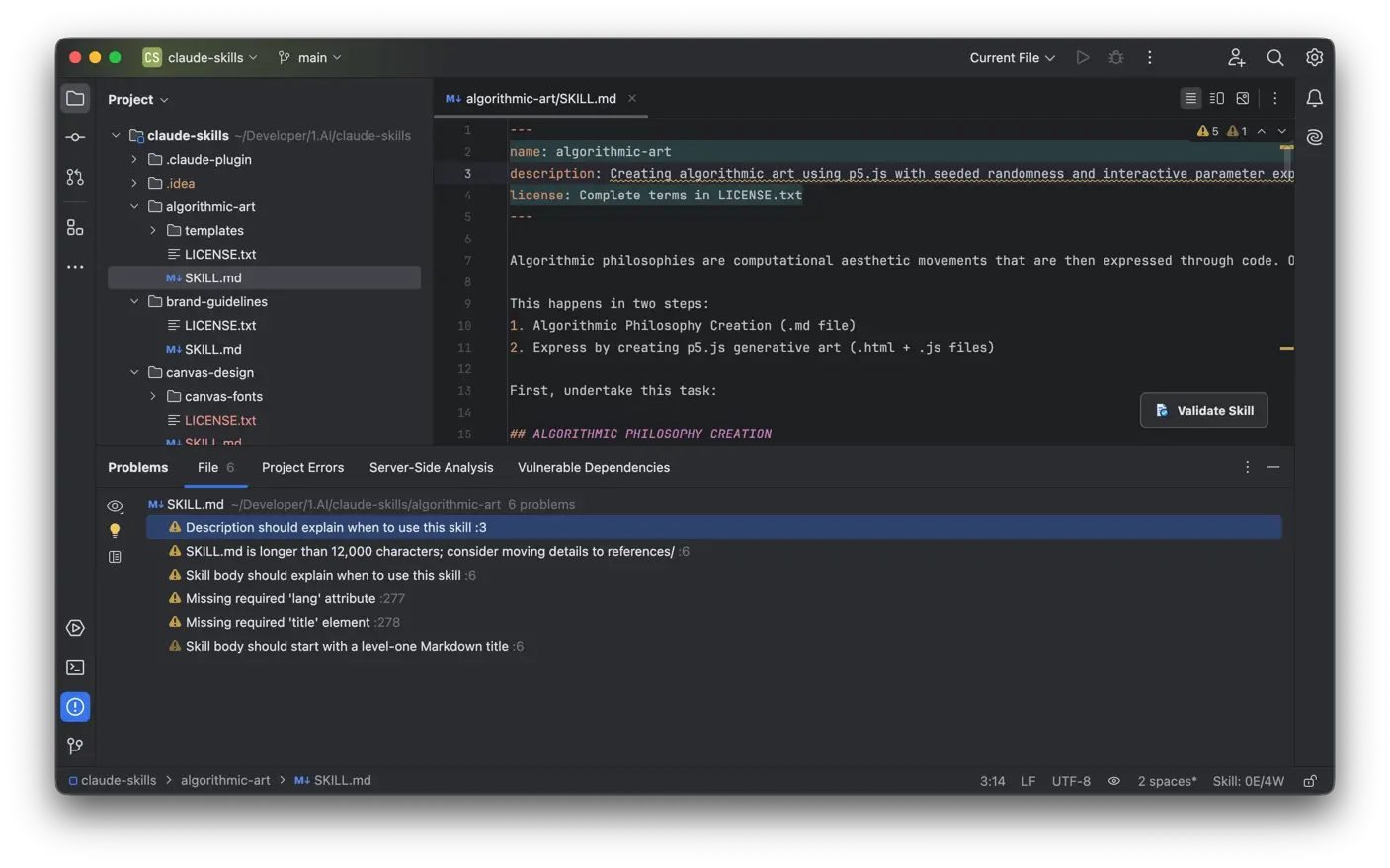
翻车现场
我自己写过的 Agent Skill, 现在回头数, 大概在十几份的量级。这十几份里面, 至少有一半在写下来的当下就是错的。
举几个典型:
name 字段写得很随意, 跟父目录名对不上 —— Agent 加载的时候按目录名走, 但匹配按 name 走, 我调了快一小时才发现 skill 根本没被识别。description 写成 “helper” 或者 “tool” 就交差了, 等到真的去用, Agent 完全不知道该在什么场景触发它, 因为没有任何触发短语 (“use when”, “when to use” 之类), AI 看了等于没看。一段 rm -rf 当时只是放在正文里当示意, 完全没想到 Agent 会把它当成可以执行的步骤直接跑。一段 references/api-design.md 的 link 引用我写完之后忘了真的把文件建出来。还有一个最尴尬的, 我把 api_key="sk-..." 直接硬编码到 skill 里某个示例脚本, 然后 push 到了开源仓库。
每一条都是低级错误, 每一条都是”如果有人在 IDE 里提醒我一句, 我根本不会犯”的错误。
Agent Skills 有官方规范, 写在 https://agentskills.io/specification, 一份并不算长的文档, 把字段语义、命名规则、引用规则、安全要求都说得清楚。但人就是不读 spec —— 包括我自己也不读。这件事不是态度问题, 是工具的问题。25 年前 PMD / Checkstyle 给 Java 设了规矩, 15 年前 ESLint 给 JavaScript 设了规矩, 5 年前 SonarLint 把这一切搬进了 IDE 里实时跑。今天 SKILL.md 的处境跟当年 JavaScript 一样, 缺一个长在 IDE 里、规则白盒、可引用、可 suppress 的 Linter。
Skill Inspector 就是这个 Linter。
拒绝”AI 觉得你这里不太好”
写这个插件的时候, 我给自己定了几条不能动的原则。其中最坚定的一条是: 每条规则都要有一个稳定的 ID, 可以 suppress, 可以引用。
听起来像废话, 但你看看现在市面上越来越多的 AI 工具, 给你的提示都是模糊的: “这里有改进空间”, “建议优化”, “Linter says no”。你不知道它依据什么规则, 不知道如何关掉, 不知道下次同样的写法它还会不会再报。这种黑盒提示, 短期看着挺智能, 长期是工程毒药。
Skill Inspector 走的是 ESLint / SonarLint 这条路。当前内置 30+ 条规则, 跨 5 个分类 —— Structural (frontmatter 缺失 / name 对不上目录 / 不是 kebab-case)、Quality (description 太泛、缺触发短语)、Reference (link 文件不存在、跨平台大小写不一致)、Resource (references/ 目录里的 dead asset)、Security (rm -rf /、疑似 secret 泄漏)。
每条规则都有一个稳定 ID, 长这样: frontmatter.name.mismatch / description.too-generic / security.secret-pattern / reference.case-mismatch。你可以在 PR review 里写 “这里违反了 description.too-generic, 改一下”, 双方对的就是同一份规则手册; 你可以在 SKILL.md 里写一句 suppress 注释关掉某一条规则; 你也可以在 issue 里报告 “我觉得 xxx 这条规则的误报率太高了, 应该收敛”, 大家围绕同一个 ID 讨论。
另一条原则是: 大部分规则要带 Quick Fix。光告诉你”这里错了”价值不大, 告诉你”按 Alt+Enter 我帮你改了”价值才大。当前 30+ 条规则里, 像 name 不匹配目录、name 不是 kebab-case、缺 frontmatter、reference 文件不存在 这些场景, 都直接带 Quick Fix —— Alt+Enter 选一下, 改完。
最后一条是: 0 外部依赖。全部走 IntelliJ Platform 原生 API, 不联网, 不收集数据, 不调任何第三方。这意味着插件在内网、离线环境、外发笔记本上的行为跟联网时完全一致。
怎么用
跟所有 IDE Inspection 插件一样, 装上之后基本不用学新东西。打开任意 SKILL.md 文件, 字段有问题的地方出现黄 / 红波浪线, 悬停看到规则 ID 和说明, Alt+Enter 调 Quick Fix。状态栏右下角显示当前文件还剩多少未修问题, Problems 面板汇总全项目所有 SKILL.md 的问题, Tools → Inspect Skill Files 一键全项目扫描。
我自己拿之前那些写得相当随意的旧 skill 测过 —— 一份, 半小时左右就能改干净。改完之后, description 不再是 “helper” 这种废话, Agent 触发命中率立刻上来; reference 链接都通了, AI 跟着 link 找资料不会扑空; 危险命令和 secret 全部清掉, 安心 push 到开源仓库。
不夸张的说, 30+ 条规则里只要命中你写过的任何一条, 这个插件就值回票价了 (反正它就免费)。
不止 30 条规则: 把它做成一个平台
写到 V2 / V3 我意识到一件事: 30+ 条规则永远不够。
我能想到的通用规则就这么些 —— 字段缺失、命名规范、危险命令、secret 模式 —— 但每个团队、每个开源项目、每家公司, 都还有自己额外的、特定语境下才成立的规则。举几个例子, 都是真实场景:
- 在 Zeka Stack 里, 每份 SKILL.md 的 frontmatter 都应该有
starter字段, 明确这份 skill 配套哪个 Spring Boot Starter。这是 Zeka Stack 的约定, 不应该写死在 Skill Inspector 里。 - 同样在 Zeka Stack 里, REST 组件下有 Servlet 和 Reactive 两个 starter, 它们的 skill
description必须显式区分两种场景, 不能含糊。这也是项目特定规则。 - 公司内部团队, 可能有合规要求: SKILL.md 不能引用任何外部域名的链接 (避免 dead link 风险), 必须全部走公司内网镜像。
- 某个开源生态 (例如某个 Agent 厂商), 可能要求 skill
name必须以特定前缀开头。
这些规则不应该塞进 Skill Inspector 的核心包 —— 装这个插件的 99% 用户不在乎 Zeka Stack 是什么, 也不在乎某家公司的合规要求。但那 1% 在乎的用户, 应该有办法把自己的规则加进来。
所以我下一步的重点不是再多写 30 条内置规则, 而是把规则引擎本身开放成扩展点。具体的设想是: 在 plugin.xml 里暴露一个 skillRule 扩展点, 第三方 IDE 插件 (比如 zeka-stack 自己的 idea plugin, 或者公司内部的研发工具集合插件) 注册一个自己的 SkillRuleProvider, 实现里返回一组自定义规则 —— 每条规则跟内置规则用同一个 SkillRule 接口, 同样有稳定 ID、严重级别、可选 Quick Fix。
这套设计完全照搬 IntelliJ Platform 自己的扩展点哲学。IDEA 自己的 Inspection 体系就是这么开放的 —— 平台提供 LocalInspectionTool 这个基础类, Java 插件加 Java 检查, Kotlin 插件加 Kotlin 检查, Sonar 插件加自己的检查, 大家共用同一份 Problems 面板和 Quick Fix 体验。Skill Inspector 应该走同一条路: 核心包提供一套通用规则 + 一个稳定的 Rule SPI, 各家生态在上面加自己的检查规则。
我设想中的接入体验大概是这样: zeka-stack 团队在他们自己的 IntelliJ 插件项目里, 写一个 ZekaStackSkillRuleProvider 类, 注册到 Skill Inspector 的扩展点, 实现里返回几条 zeka-stack 特定的规则。用户同时装上 Skill Inspector 和 Zeka Stack IDEA 插件后, 在任何一份 SKILL.md 里都会自动跑这些扩展规则, 体验上跟内置规则毫无差别。如果只装了 Skill Inspector, 就只跑内置那 30+ 条。
这套扩展接口让 Skill Inspector 从一个规则集升级成一个规则引擎。我自己后续会在 Zeka Stack 的 IDEA 插件里第一个吃自己的狗粮, 把 zeka-stack 特有的几条规则做出来, 顺便把接口磨光。如果接口稳了, 后面想为别家生态加规则的人也能照搬。
一个还在路上的 AI 集成
确定性规则的天花板在哪? 当前这 30+ 条都是白盒、可推导的 —— 字段对不对、命名合不合法、link 通不通、有没有疑似 secret —— 这些都能用文本匹配或简单 PSI 分析判断。
但很多关于 SKILL.md 的判断, 本质是 fuzzy 的, 确定性规则写不出来:
- 这条
description真的能让 Agent 在正确场景被触发吗? - 这段正文写得清楚吗? Agent 读完真的能照做吗?
- 这个 skill 跟项目里已经存在的另一个 skill 是不是功能重复了?
- 给定一段需求, 应不应该新写一个 skill, 还是复用现有的?
这些问题, 确定性 lint 答不了, 但 LLM 可以。我打算后续在 Skill Inspector 里加一个 “AI Review” 模式 —— 跟现有规则平行的另一类 inspection, 走 LLM 给 fuzzy 建议, 但同样以 Problems 面板里条目的形式呈现, 保留可解释、可 suppress 的体验。不替代当前的确定性规则, 而是补全它。底层会接 IntelliAI Engine, 跟我其他几个 AI 插件共用同一个多服务商接入层, 不绑定某家。
这部分还没动手, 因为我想先把扩展接口磨稳 —— 内置规则白盒、扩展规则白盒、AI 规则同样可解释, 三者用一致的体验呈现给用户, 这个事情想清楚再写代码。
下载和源码
- JetBrains Marketplace: https://plugins.jetbrains.com/plugin/31938
- 开源仓库: https://github.com/dong4j/skill-inspector
- 官网 / 完整规则手册: https://skill-inspector.dong4j.site
- Agent Skills 官方规范: https://agentskills.io/specification
- 作者其他 JetBrains 插件 (vendor 页): https://plugins.jetbrains.com/vendor/9afaba35-91ea-4364-8ced-64db868dd23e
Java 21, 兼容 IntelliJ IDEA 2024.2 → 2025.x, MIT 协议。
如果你正在写 Agent Skill, 哪怕只写过一两个, 装上跑一遍试试。
相关阅读
- SkillsJars Helper —— Agent Skill 的 Maven 装包器, 解决”skill 怎么跟着 SDK 一起分发”的问题。Skill Inspector 帮你写好 skill, SkillsJars Helper 帮你分发和消费 skill, 两端互补。
- IntelliAI Changelog —— 用 AI 一键生成 Changelog / 日报 / 周报 / commit message。跟未来的 “AI Review” 模式共用底层引擎。
- IntelliAI Engine —— 多 AI 服务商统一接入层, 上面几个 AI 插件的 backend。



























